
Handling Dynamic Column Headers with Azure Data Factory Mapping Dataflows
Dealing with dynamically changing column names or changing schema at the source level makes it complicated to consume the files using data pipelines. Let us take a look at the following scenario.
Assume an excel file is getting delivered into a BLOB storage container based on a periodic schedule. In every file, we receive on the BLOB storage one particular column name is being changed dynamically. Since the schema of excel is changing, it becomes difficult to read the data.
ADF Mapping Data Flows will help us to handle this type of situation.
What are mapping data flows?
Mapping data flows are visually designed data transformations in Azure Data Factory. Data flows allow data engineers to develop data transformation logic without writing code. The resulting data flows are executed as activities within Azure Data Factory pipelines that use scaled-out Apache Spark clusters
Let’s go through step-by-step how this could be achieved.
Pre-Requisites
Azure Account, Azure SQL Server, Azure BLOB storage Account (with Storage Contributor role) & Azure Data Factory,
Linked Services created from ADF to Azure BLOB and Azure SQL. Link
Sample Excel file

Destination

Let us initially create the input dataset and the output dataset on ADF. Input dataset will be created using the Linked Service to Azure BLOB Storage. Note that onread is the private container name inside BLOB Storage, you can create and name the container based on your requirement.
Input Dataset

Output Dataset will be created using Azure SQL Linked service.
Output Dataset

Before we dig into more details of the Dataflow let’s have a glance at the Dataflow which consists of one schema modifier along with source and sink(destination).
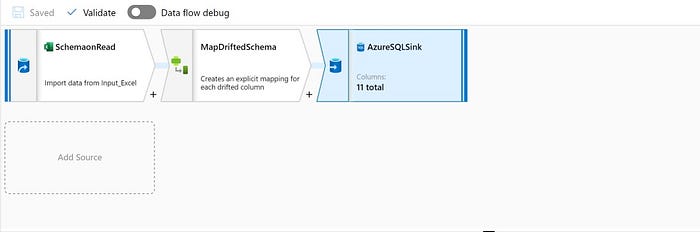
The initial step of the data flow would be to connect the source using the source dataset we already created. In Source settings Allow schema drift needs to be ticked.

The next step would be to add a schema modifier Derived Column. This is where the dynamic column is mapped using the byPosition() function. This function will allow you to read the dynamic column based on the column position, so the dynamic nature of the column name would not become an issue. The same value of the dynamic column is split into Year, Month, and Type and mapped to relevant destination columns as well. This is achieved using columnNames() which allows us to access the column names as a list by using [n] position.
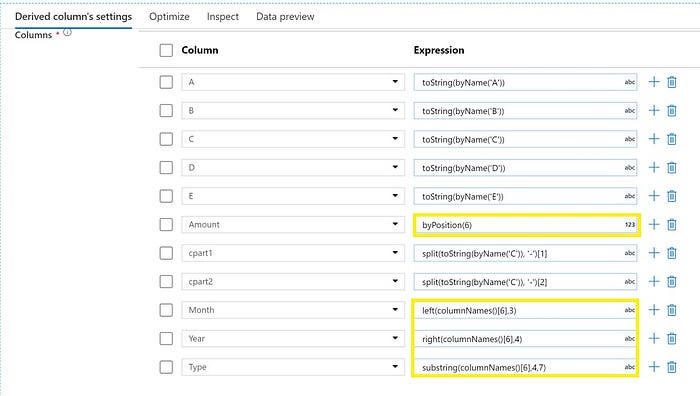
As further transformations, I have applied the split function for column C. If the debug dataflow session is turned on you will able to see the output from the data preview tab. It will display the data from the original source along with the derived values.

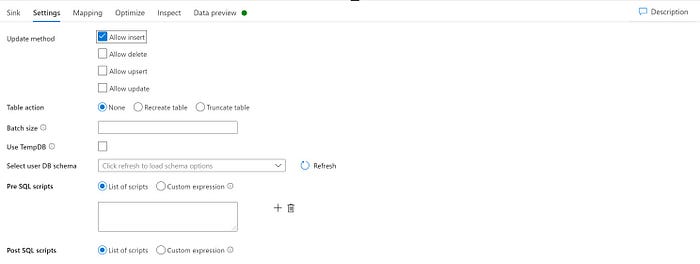
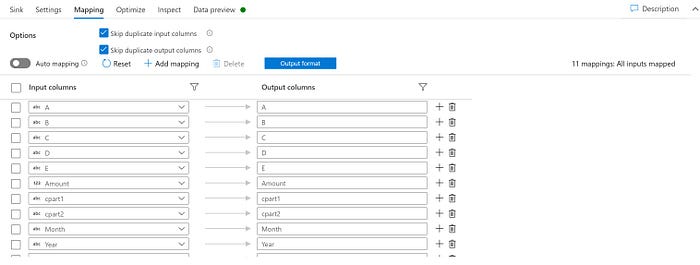
The final step would be to map the derived schema to the Azure SQL Sink. Settings and Mappings are as follows. Allow Schema Drift should be turned-on in the sink as well.

Now you will be able to debug this flow. Note, it will take few minutes to start the flow since under the hood an Azure Databricks cluster will be spun up to execute this flow. This data flow can be added inside a data pipeline and orchestrated based on your requirement.
